2 недели назад я решила прыгнуть в кроличью нору и попробовала кодить с ИИ. Лучший способ изучить любой инструмент — не смотреть видео (это можно делать бесконечно без результата), а сделать свой конкретный маленький проект и набить шишки.
Спойлер. Проект оказался не один, а сразу 5, и останавливаться я не планирую. Но обо всём по порядку.
Стартовый уровень
Я в последний раз программировала в школе в 2002 году (BASIC, Pascal), но много управляла разработкой. Поэтому, конечно, мой уровень на старте был не нулевой. Например, увидев затемнённую фотку, я сразу попросила «проверить, есть ли чёрный оверлей поверх». Или, когда небоскрёб закрыло надписью, предложила отмасштабировать (кропнуть) фото. Это очень простые и логичные правки, вовсе не rocket science, но для новичка они были бы не очевидны.
Может ли полный новичок кодить с ИИ? Да, но а). потребуется время на выработку эффективной модели работы, б). логичному технарю будет проще, чем гуманитарию (будет сильно мешать «изысканный жираф»), в). желательно снизить свои требования (хотя бы временно).
Самое первое приложение
Триггером послужило обновление Твиттера. Раньше можно было кликнуть на латышскую новость, сразу, в том же окне увидеть перевод и учить новые слова. Обновление сломало мой привычный паттерн изучения языка.
С еле сдерживаемым криком «Отомстим Илону Маску!» я открыла Perplexity Computer, чтобы где-нибудь за час сделать своё приложение. Понадобилось 5 часов и 19 сборок, но задача была решена.
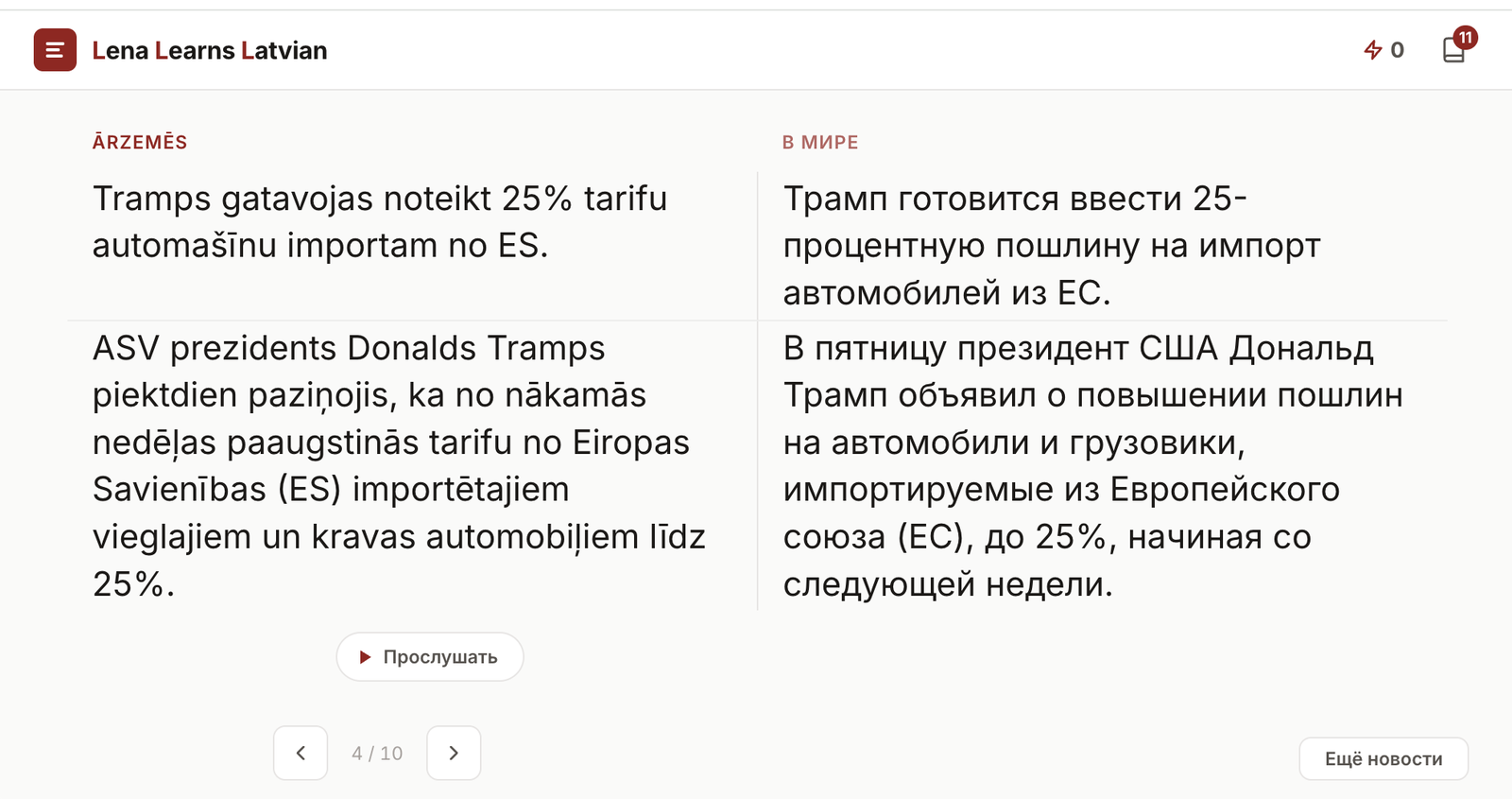
Новости подтягивались из Delfi, перевод мгновенно отображался через API, озвучка работала (совсем без акцента и не роботизировано), новые слова добавлялись в словарь, календарь со стрик рисовался, мобильная версия работала и даже фавикон был в виде латышского флага — красота!
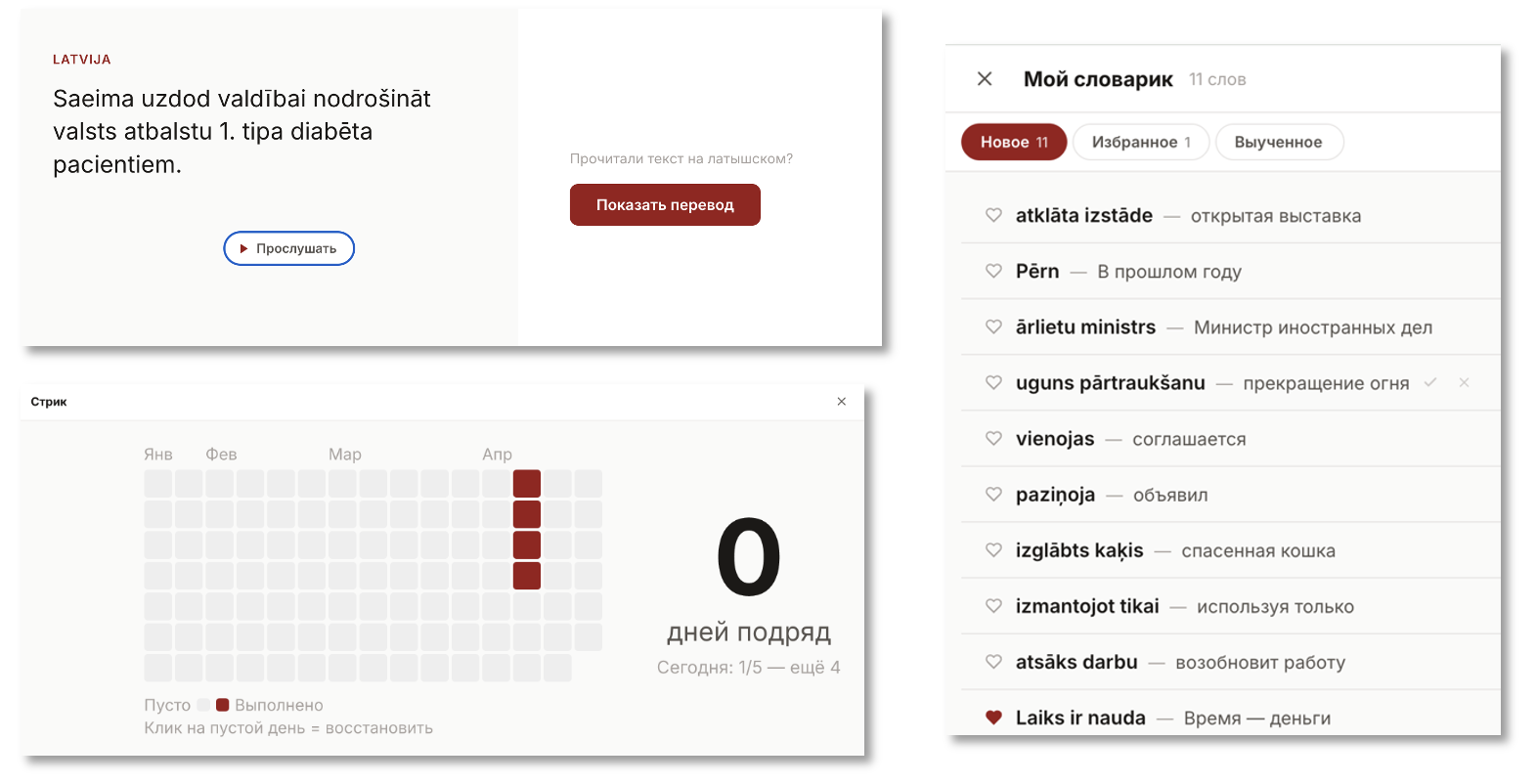
Конечно, первое приложение было самым простым. Я его сделаю частью (одной из вкладок) большого приложения LLL (Lena Learns Latvian) и обновлю дизайн. Старую версию можно посмотреть здесь на Гитхабе.
Так как кодит ИИ?
Процесс выглядит как обычная переписка. Например, я хочу сделать перевод с латышского на русский. Спрашиваю: «Слушай, а вообще такое бывает, где, сколько стоит?» Чат даёт варианты. Я иду в сервис. Если где-то застреваю, присылаю скриншот и он помогает: «Нет, API-ключи раздают на другой вкладке, иди туда».
При этом ИИ рассуждает вслух и это можно читать как роман.

Второй подход к снаряду. Сайт фэмили-офиса.
Дальше я решила сделать сайт фэмили-офиса. Надоели вопросы: «А чем ты теперь занимаешь?» А вот этим.
Опыта было мало, и я много времени убила на поиск референса/сетки, а потом главного изображения.

Мне хватило ума остановиться и не делать анимацию (мигание окон в небоскрёбах), т.к. мы бы месяц привязывали координатную сетку с ИИ. А без сетки мигать будет звёздное небо над нами и над Уолл-стрит, а не окна.
Типографика как бы газетная. Референс — Wall Steet Journal.

Кажется, получилось «дорохо-бохато». И в вебе, и на мобилке. Но в сайтах главное что? Правильно, фа-ви-кон. Фавикон не забыт. Идём дальше.
Третий шаг. Игра Connections.
В игре нужно объединять слова в группы. Очень затягивает, если вы гик.
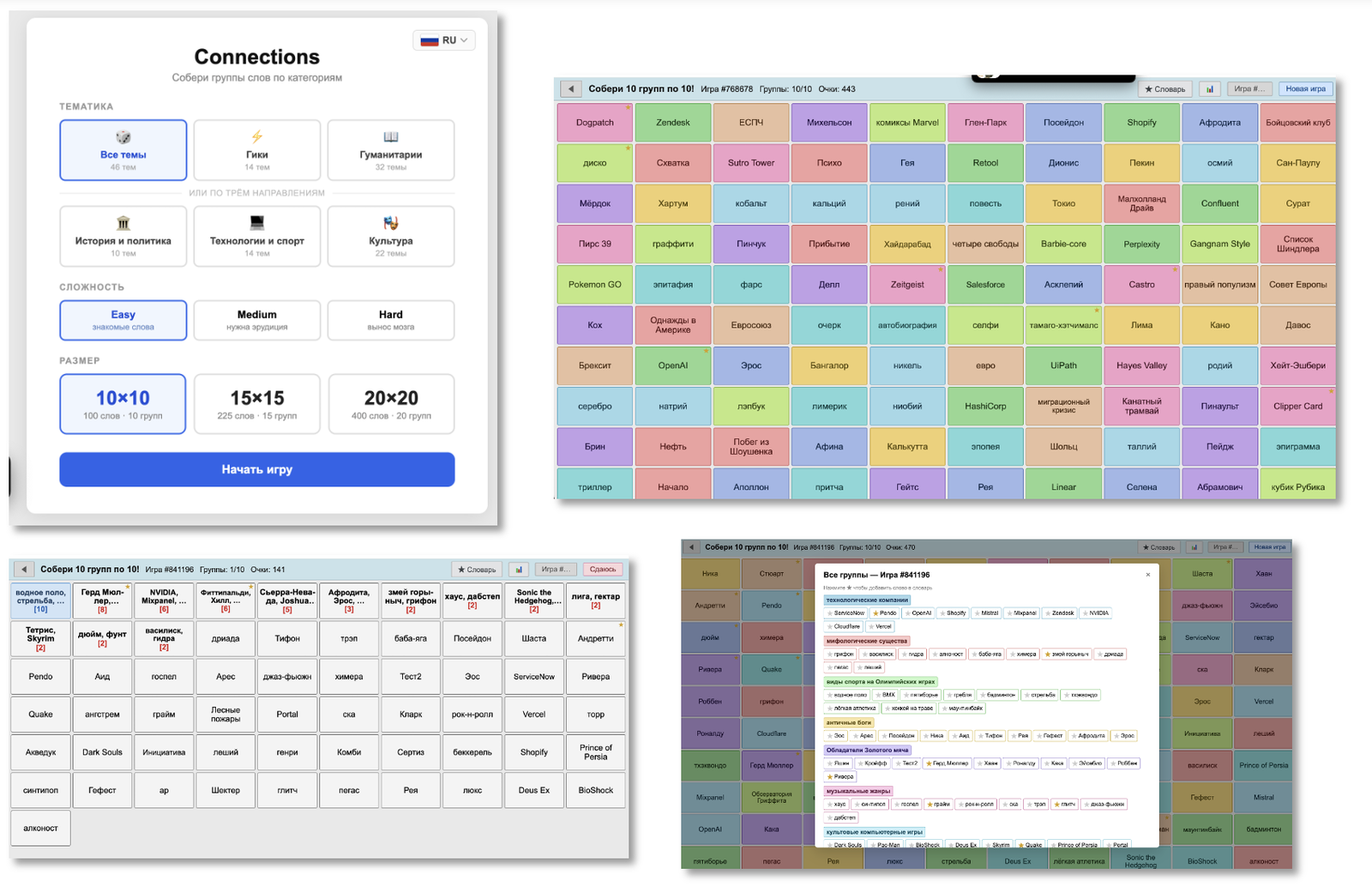
Технически нужно было собрать механику метчинга, наборы слов (около 5 тысяч слов), протестировать на дубли, отловить перлы, вроде «Сносная лёгкость бытия», сделать английскую версию и лёгкий режим для всех, кто не играл в моей команде «Что? Где? Когда?».
Четвёртое. Личный сайт.
Этот сайт. Технически это чужая готовая сетка (блог Вани Замесина), теги к постам, блок рекомендаций, конвертация постов из ворда в язык Markdown, рассылка.
Пятое. Сервис изучения языка.
Интервальное повторение карточек. Можно посмотреть здесь.
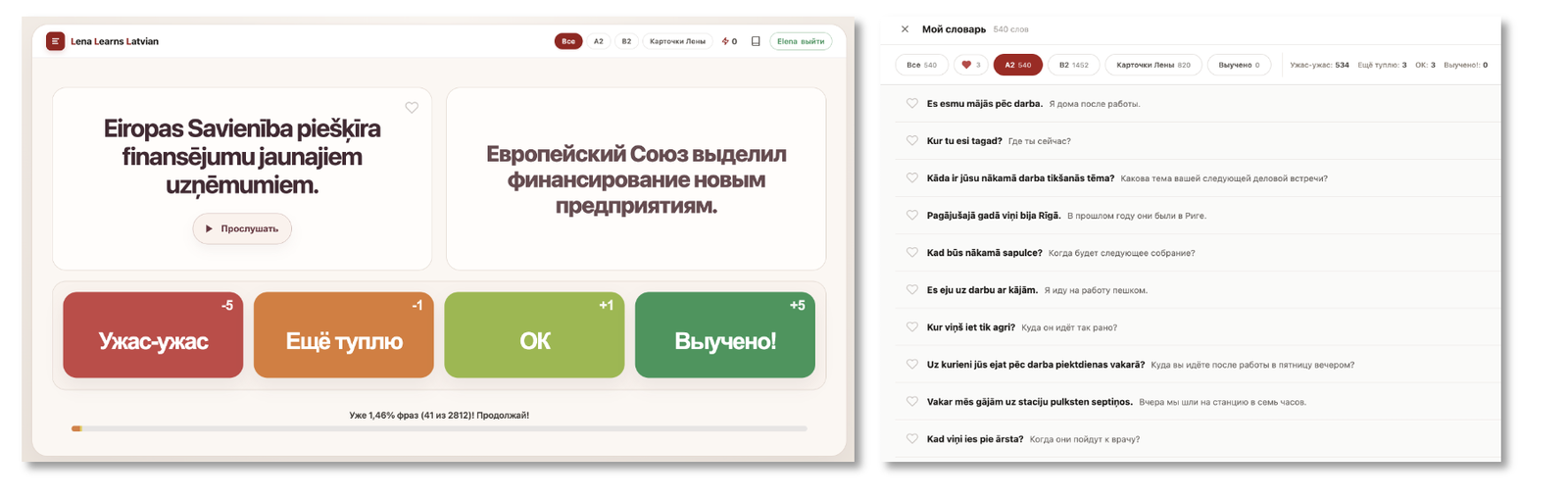
Технически это, как и в самом первом приложении, перевод, озвучка без акцента, словарь, стрик, мобильная вёрстка. Из нового а). пришлось настроить логин через Supabase (т.к. хранение данных в браузере ненадёжно, не хотелось бы через 2 месяца зайти и обнаружить, что всё стёрлось), б). логика интервальных повторений карточек, в). мотивирующий прогресс-бар.
Но главное — какие именно слова отобраны. Я (мы) нашли списки частотных глаголов и вообще слов в языке и отобрали те 2000, которые употребляются чаще всего. Для самых употребимых глаголов я попросила сделать 5 фраз по логике 1-3-1 (прошедшее — настоящее в 3 формах — будущее). Дальше нашли массив текстов, используемых для подготовки к экзамену, прогнали его, вытащили из него частотные слова. Выяснили, что 85% и так были собраны раньше, т.е. задача была сделана хорошо. Добавили новые.
Я бы и дальше развлекалась, но, к сожалению, уже пришлось непосредственно учить язык. Жаль.
В следующем посте расскажу про свои выводы и советы по ИИ-кодингу.